
Reading Notes: A Short Introduction To Queueing Theory
I'm about to change role in my company. In order to prepare I looked for introductions to queueing theory. I found the paper from Andreas Willig: A Short Introduction To Queueing Theory. The books available on Amazon are awfully expensive... So I turned to this paper instead.
Basic Model and Notation
Queues can be used to model telephone systems, airport security lines or similar systems. The basic model looks like the following schema:
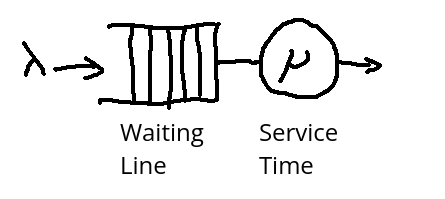
Queues are discribed with the Kendall notation A/S/c/K/N. Each letter correspond to a characteristic of the queue:
- A is the arrival rate of tasks
- S is the service time discribution
- c is the number of servers that process tasks
- K is the number of places in the queue, we ignore this one
- N is the population of tasks, we ignore this one
- D is the queue discipline
There are many discipline available, such as First In First Out (FIFO). But you can also think of priority queueing, process sharing, etc. We'll only consider LIFO for the rest of the article.
We need to talk about μ and λ as well. To agree on notation, let's also talk of other conventions:
- W is the waiting time of a task
- B is the service time, time for a task to stay in the process
- S is the response time, i.e. W + B
- λ is the mean arrival rate of tasks
- μ is the mean service rate of tasks
- L the number of tasks in the queue (either waiting or serviced)
Little's Law
Now that's a lot of notation to digest. The paper is a better than me at introducing them in the right order. They are key to discuss the theory results.
The first result from queueing theory is Little's Law. It is the simple formula:
mean(L) = λ.mean(S)
This formula can be applied to a lot of systems. It is also quite intuitive. The more tasks are submitted, or the slowest the process gets, the larger the number of tasks in the queue. It does not seem much but it's used everywhere in the theory.
Utilization of the queue
Utilization is an important parameter for queues. The closer the utilization gets to 1, the larger the number of tasks in the queue. The paper shows the case for M/M/1 queues (here M is the Markovian distribution):
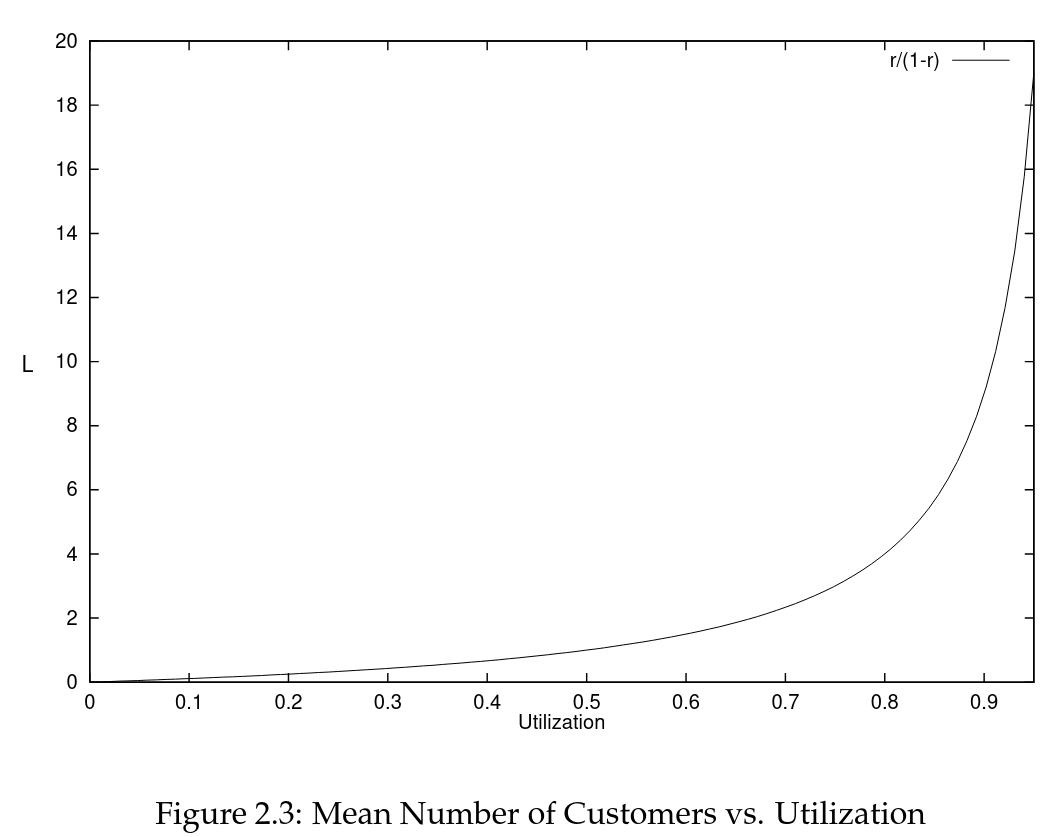
When we optimize a system, it automatically raises the number of tasks waiting. As a result of Little's Law, it means that the mean response time of the system increases. This is something to have in mind when designing systems.
Horizontal vs Vertical scaling
When it comes to scaling, the hype has been towards horizontal scaling (having more service nodes). On the other hand, vertical scaling (buffing up the server node) is not much considered. Let's see what queueing theory can teach us.
Say we want to serve 20 customers. Is it better to have 20 nodes with a service rate of μ or a single node with a 20μ service rate? Both queues can respond to 20 tasks per seconds. Which queue performs best in your opinion?
The result is quite astounding:
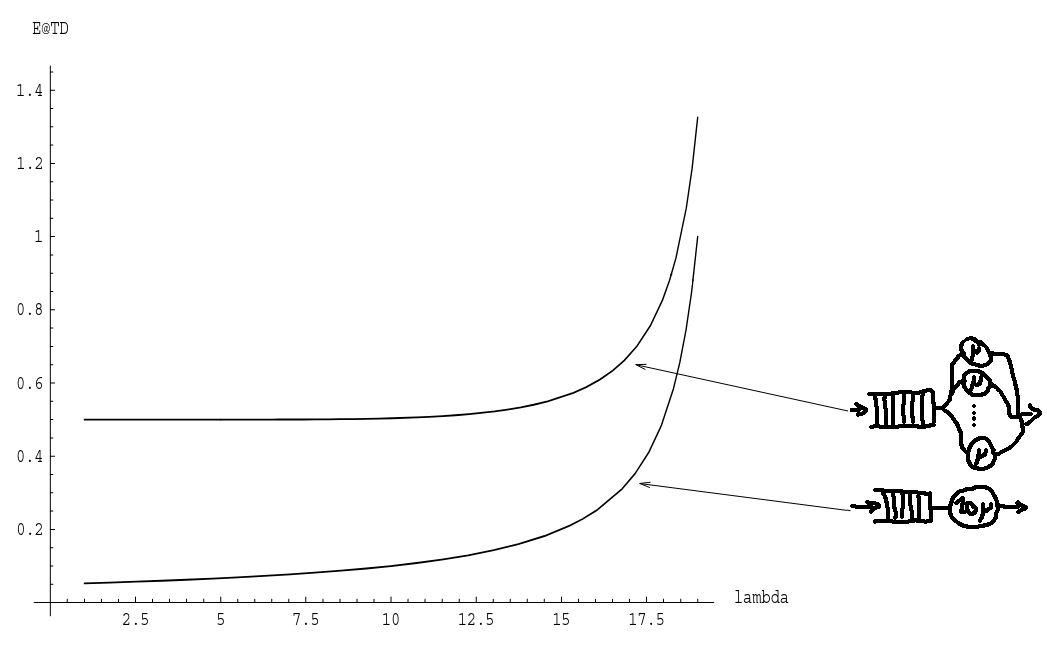
The plot represents response times for each systems. The fat node wins for every value of λ. This is a surprise to me. We tend to favor horizontal scaling to vertical scaling. Maybe vertical scaling is not that bad!
Effect of variance on queue length
The final result I noted in the paper is the Pollaczek-Khintchine Mean Value Formula. I won't write the exact formula here. But basically it states that the shape of service time distribution has an impact on the number of tasks in the systems. The formula can calculate the mean number of tasks with the given parameters:
- λ the mean arrival rate
- μ: the mean service rate
- E[S] the mean service time
- Var[S] the variance service time
Given C is the following: C = Var[S] / E[S]². The mean number of tasks follow the following graph:
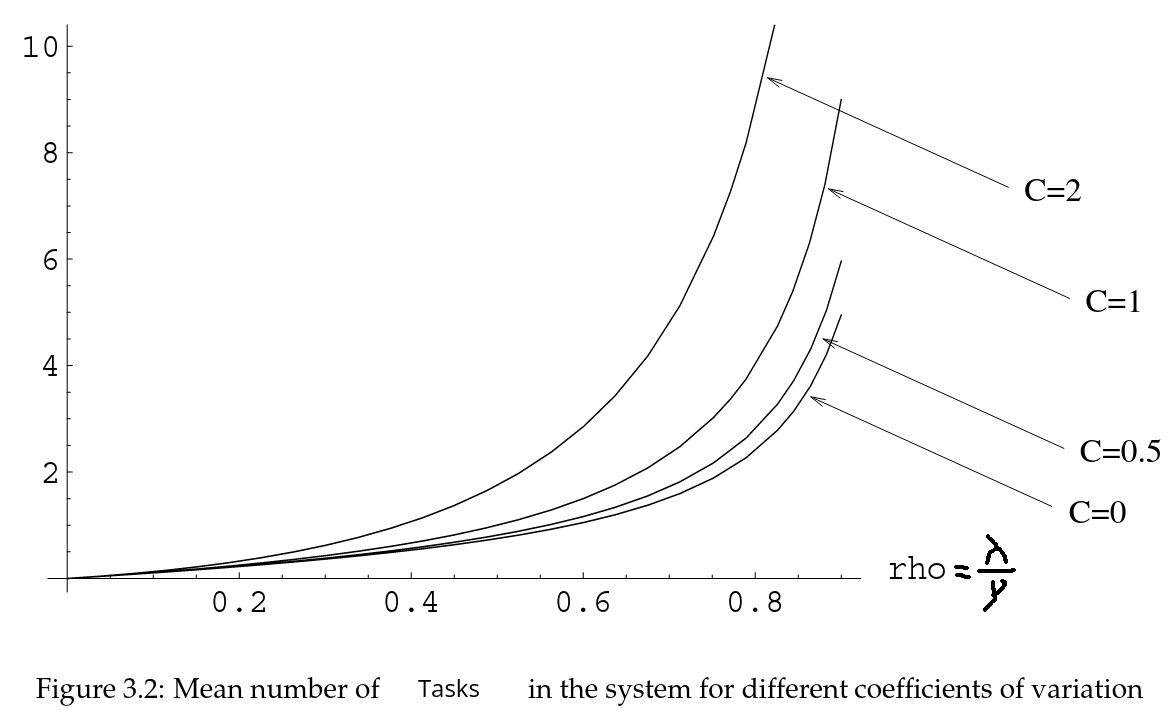
I've always wondered how variance impacted systems. A long time ago, I experimented four different languages performance distribution. They had very different distributions. Erlang was the most predictable language of the four. What a coincidence!
Conclusion
I'm about to work on very systems very similar to queues. I searched for a good introduction and this paper is exactly that. It's very well written and introduces every concepts at a slow pace.
I hope to use this knowledge very soon. If I do, I'll write another blog post.
Take care.