
Reading notes: SLOG: Serializable, Low-latency, Geo-replicated Transactions
The Serializable, Low-latency, Geo-replicated Transactions (SLOG) paper is an attempt at providing the best characteristics to transactions. It was implemented in open-source Calvin and is offered by Fauna.
The paper starts pointing out existing databases have to drop one of the following properties:
- Strict Serializability: Cassandra, Riak, and Dynamo do not offer this guarantee to their transactions
- Low-latency writes: Spanner, Cosmodb, and Calvin requires a WAN RTT (high latency) to issue writes
- Throughput: for cross-region transactions, NuoDB requires coordination over WAN, so throughput is sacrificed
SLOG uses an approach close to PNUTS. Data is organized in granules. Each granule has a home, a region responsible for its integrity. Transactions that access the same region are very quick because there is no cross-region communication.
To have strict serializable, low-latency, and cross-region transactions, SLOG leverages a deterministic execution framework. It has knowledge of all the granules and the operations when the transaction begins. This means that transactions cannot be interactive like regular SQL systems. The paper does not insist on the caveat. Although an discussion on the reasons of the decision are out of the scope of the paper,
SLOG does not remaster granules (changing granule home region) during transactions. It issues special transactions to remaster granules.
SLOG implementation
The authors implemented SLOG in the existing Calvin database. Calvin used a Paxos global ordering of all transactions (cross-region or not). SLOG replaces this component with a local ordering of transactions.
Every region consists of a local log ordered by a Paxos consensus. It asynchronously synchronizes with other regions' logs. Since every region controls its granules, logs can be recombined in any order to form a global log.
Single-home transactions are put in the local log of the home region. Multi-home transactions are partially executed by every region. They issue a special LockOnlyTxn log entry which gets replicated like single-home transactions. SLOG can be interpreted as 2 phase locking (2PL) on each granule.
The difficulty comes with remastering data. The authora solve the issue with an elegant solution. Each granule locally contains meta-data on the last accesses. When the last three accesses are from another region, a remastering transaction is performed. Whenever a transaction is applied to the granule the count of access is verified and if it does not conform, the current transaction is aborted. It means that every region can independently abort transactions that are issued to the wrong region.
Experiments
The experiments leave me confused. Let's look at the latency chart:
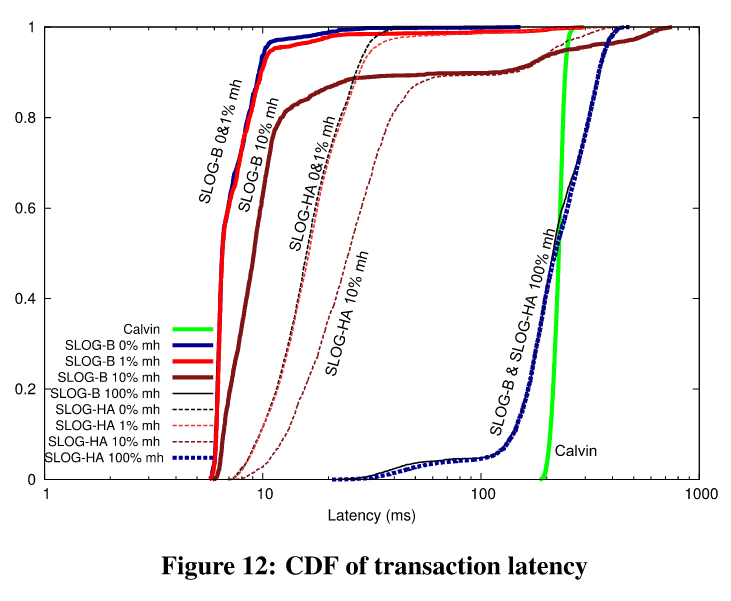
If we take the SLOG-B with 10% multi-home (mh on the graph) transactions, the profile is concerning. 90% of transactions have an order of magnitude less latency than Calvin, but about 5% of them are above the 200ms latency. This tail-latency is quite concerning. It means that SLOG is great for most workloads but some systems might suffer from SLOG as well.
The paper also attempts at comparing itself to Google Spanner. SLOG does not allow interactive transactions while Spanner does. This makes the comparison quite unfair.
Conclusion
The paper is really interesting, SLOG might not be universally applicable, but it offers some really smart solutions. I want to discuss the approach of Calvin.
Non-interactive transactions allow Calvin and SLOG to offer very performant systems. I don't think their approach will work for OLTP workload though. Non-interactive transactions mean that the application developers need to rely on the database internals to implement the domain logic. In my experience, it has never been a paying tradeoff. Updates in the business logic are more difficult to deploy and maintain.
It also means that any change to Calvin internals can have a huge impact on the code. Read how difficult it is for Facebook to upgrade mysql in their review. This issue is out of the scope of the paper but I needed to spit it out!
Take care!